ML Models and Information Compression
Machine Learning models are systems that learn patterns from data. This perspective has been prevalent in the era of traditional ML models, such as Logistic Regression and Random Forests. However, Deep Learning has significantly expanded the capabilities of ML models and enabled these models not only be optimised for the target metric but unintentionally serve as information compression systems for the training data.
For example, the training process of models like LLaMA 7B effectively compresses ~4.7TB of data into ~13GB of model weights:
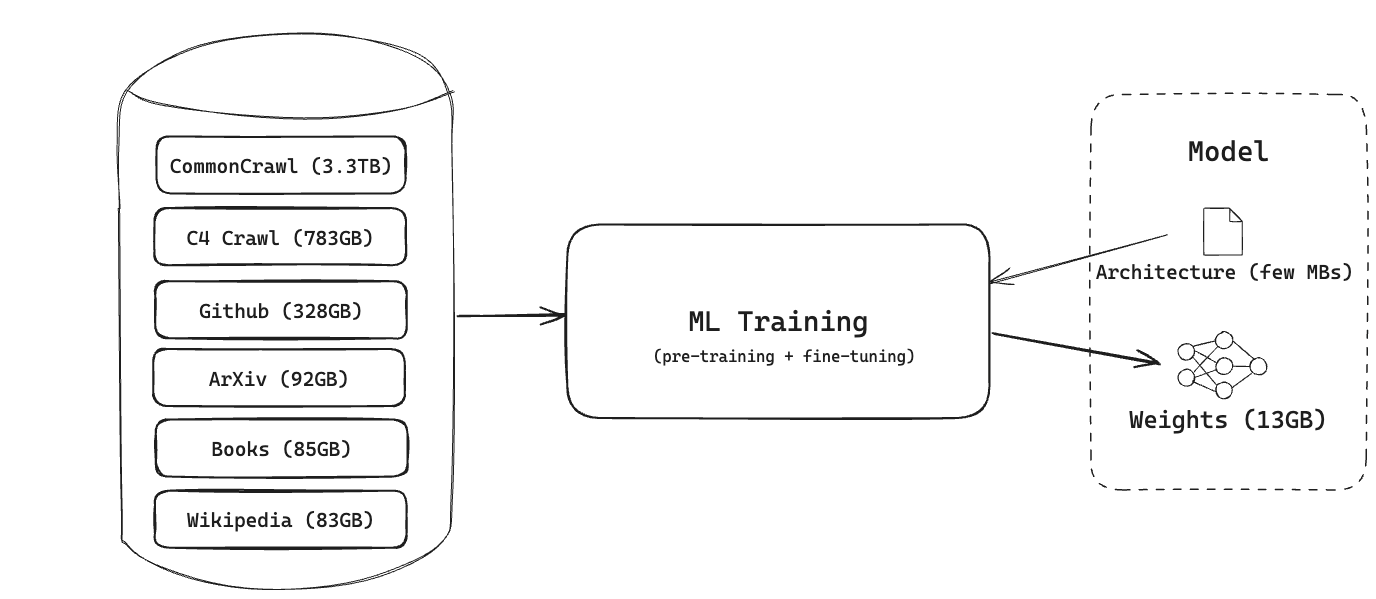
Inputs and outputs of model training. Example: LLaMA 7B
ML and Information Theory
From an information theory standpoint, ML models aim to minimize the description length of the training data following the principle of Minimum Description Length. They strive to distill and encapsulate the initial information and downstream intermediate representations (features) into a space constrained by the model’s architecture and the size of its trainable weights.
From a deep learning perspective, each layer is conceptualized as transforming the data into progressively more abstract and compact representations. This process filters out redundant or irrelevant information, preserving only what is essential for the task at hand.
Essentially, ML models leverage information compression as an intrinsic mechanism to enhance their ability to generalize to unseen data. By reducing the entropy of the output given the input, they effectively compress the information required to describe the mapping from inputs to outputs.
ML-based data compression
The recent research findings from DeepMind demonstrate that LLMs can outperform standard and widely-used compression algorithms in terms of final data size. Remarkably, even models initially trained solely on text have been shown to function as general-purpose lossless compressors:
- audio is reduced to 16.4% of its original size, outperforming FLAC
- images are compresses to 43.4%, surpassing PNG.
Additionally, previous studies show that DNNs of various architectures (autoencoders, feedforward networks, transformers) are capable of executing both lossy and lossless compression.
Compression as an ML method
Exploring the intersection of compression and machine learning from a reverse angle led to some interesting insights.
The “Less is More: Parameter-Free Text Classification with Gzip” paper utilizes the Gzip compression algorithm in conjunction with a basic k-nearest-neighbor classifier to address text classification challenges. This idea, which has been surfacing in the tech community for a while, demonstrates connections between compression and generalization concepts.
Model and input compaction
Model distillation
Model distillation is a technique where a larger, more complex ’teacher’ model transfers its knowledge to a smaller ‘student’ model. This process can dramatically reduce the size of the model’s parameters, sometimes by several orders of magnitude, effectively compressing the information contained within the model while retaining its ability to make accurate predictions.
Quantisation
Quantization represents a more technical strategy aimed at optimizing the storage of each model parameter. By reducing the precision of the parameters (e.g. from 32-bit floating-point to 8-bit integers) both the memory requirements and the computational load during inference are significantly decreased.
LLM prompt optimisation
Natural language serves as input/output interface for LLMs. Human languages inherently contain a significant amount of redundancy. Projects like LLMLingua tackle this problem by compressing input prompt to a much smaller (up to 20x) format not necessarily comprehensible by humans but optimized for LLMs. This compression both optimizes inference time and can reduce API call costs.