Prompt, Parse, Extract: LLMs on the Web
The Web is estimated to contain 400B of documents, and this number continues to grow. With the Semantic Web largely failing to deliver on its promise to enable computers and people to work together on structured data, the need to automatically extract information from vast unstructured corpora of data has never been greater.
LLMs offer new possibilities in this field. The tradeoff between their deep capacity but high costs underscores the need to identify system design patterns for efficient LLM-based information retrieval.
Advanced web content extraction
A natural approach is to employ LLMs at the web page text processing stage. We can pass outputs from crawlers (such as Scrapy or requests library) and then prompt the LLM to extract and analyze specific data fields.
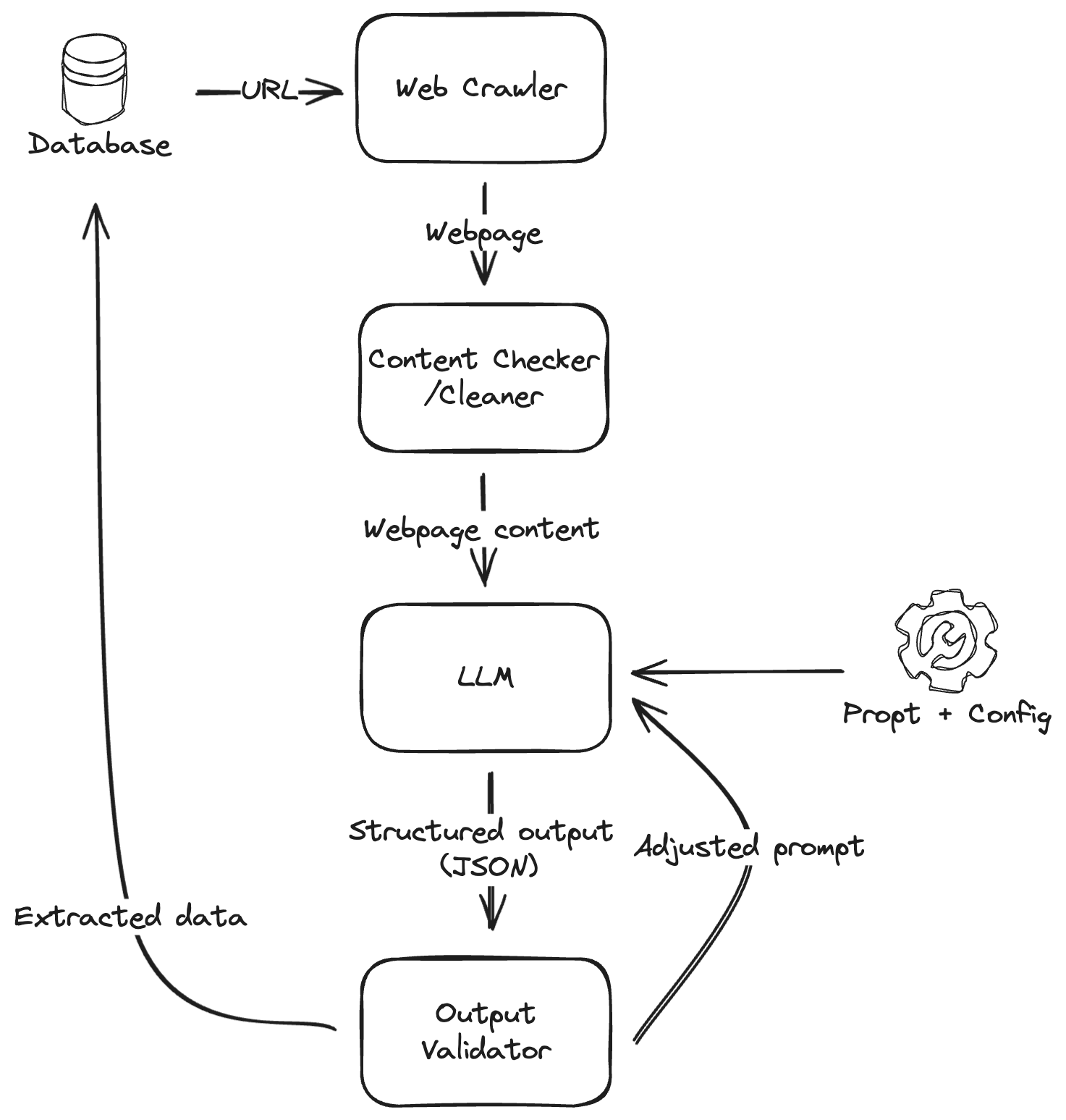
Using LLMs to extract web page content elements
Using intermediate semi-structured format
LLMs are capable of processing both raw HTML+JavaScript as well as cleaned text. While handling raw content allows for the preservation of more contextual information, it also increases computational costs and execution complexity. Alternatively, using already cleaned text (processed through tools like BeautifulSoup, lxml or html5lib) significantly reduces the number of tokens required for processing but may omit important structural details of the content.
A balanced alternative is to convert raw HTML into Markdown before passing it to the LLM. This method maintains essential content structure, such as paragraphs, links, and tables, while mitigating issues related to processing large amounts of data, commonly referred to as context window size issues. It ensures an efficient balance between preserving the content’s context and minimizing computational demands.
Built-in post processing
In addition to simply extracting data, models can perform further processing in areas where they excel, including:
- Summarisation
- Classification
- Context-aware filtering
- Sentiment analysis
- Translation
- Automatic output formatting (JSON, CSV)
This post-processing is already built into the capabilities of LLMs and allows for leveraging the full range of their functionalities.
Ensuring structured outputs
As with many complex systems, LLMs can exhibit non-deterministic and chaotic behavior, leading to unpredictable outputs. While there is no one-size-fits-all solution to completely eliminate this issue, employing a combination of techniques can significantly improve reliability:
- Prompt engineering: Crafting explicit instructions and templates to guide the model’s output.
- Few-shot learning: Providing the model with examples that include the expected output format to help it learn by analogy.
- Reducing temperature: Lowering the randomness in the generation process (temperature setting) to increase the likelihood of generating valid and structured outputs.
- Fine-tuning: Custom training on a specific dataset tailored to the desired output format. This method involves considerable computational and possibly financial costs.
- Auto retry: Implementing scripts to validate outputs and iteratively adjust the prompt if necessary to correct format discrepancies.
Multi-modal web page processing
Web pages are primarily designed for visual consumption by humans. For use cases that require a deeper understanding of a page, we can enhance analysis by simultaneously providing LLMs with both the webpage’s text and a rendered screenshot. This multi-modal approach allows the models to process visual elements alongside textual content, offering a more comprehensive web page understanding.
Danger of prompt injection
Prompt injection represents a significant pitfall in web data processing with LLMs. This vulnerability involves malicious users crafting inputs that manipulate the model’s output, potentially leading to undesired or harmful results. The rising concerns over prompt injection underscore the critical importance of input validation and sanitisation in web scraping projects.
Automatic web scraper generation
Processing web content with LLMs is highly effective for one-off extractions and analyzes but can face scalability challenges when dealing with thousands of pages. An efficient solution to scale web scraping efforts, especially for sites with a similar structure, is to use LLMs to generate web scraping parameters.
LLMs can periodically identify the target web element selectors (such as XPath or CSS selectors) from a few examples. Then this configuration can be passed to web crawlers to take advantage of developed and highly-scalable existing scraping infrastructure.
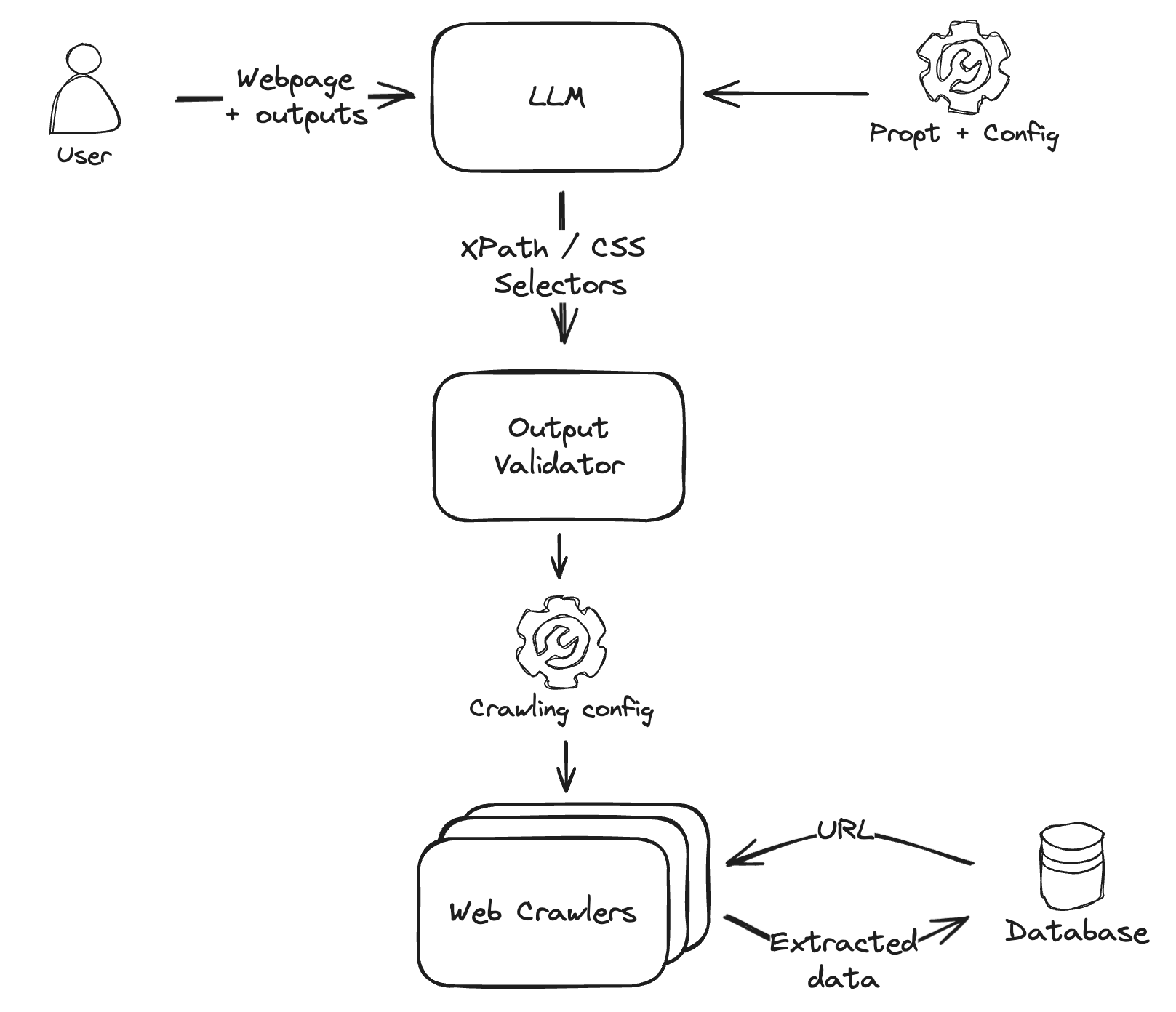
Using LLMs to generate parameters for web crawlers
LLMs as web agents
A currently experimental domain is to treat LLMs as agents autonomously interacting with websites. While models like ChatGPT and Gemini showcase capabilities in this area, they are currently restricted to crawling only search engine results rather than arbitrary websites due to privacy and security considerations.
Ongoing research demonstrates that LLMs can serve as generalist agents, capable of learning the UI structure of web pages and performing complex actions like filling in web forms and navigating dynamic content.
Other proof of concept projects like Web LLM tackle this issue from another perspective by bringing the full LLM inference inside the browser. Such method addresses privacy concerns and introduces the way for LLMs to act as autonomous web agents on users’ behalf with direct and secure web interactions.