Embeddings in the LLM Era
Large Language Models have not only revolutionized the field of Natural Language Processing but have also ignited a global wave of rapid breakthroughs in Generative AI. One intriguing question that arises in this landscape is: What is the current role of previous state-of-the-art NLP techniques like Text Embeddings?
In simple terms, embeddings are numerical vector representations of information, whether it’s text, images, or even the output from a previous block of a Deep Neural Network. These representations capture semantic meaning through iterative adjustments of values via backpropagation.

Illustration of Embeddings generated by DALL-E
Building blocks of LLMs
The trained input embeddings layer is one of the five fundamental components of the Transformers architecture powering all of today’s top LLMs. (in addition to positional encoding, the attention mechanism, a fully-connected layer, and the softmax output). Importantly, there is no known alternative for converting natural text into numerical vectors. These vectors are indispensable for both machine learning algorithms and the underlying computer hardware.
For instance, many LLMs, from the original “Attention Is All You Need” paper in 2017 to GPT-4 Turbo in 2023, continue to utilize the Byte Pair Encoding (BPE) embeddings technique. BPE, initially introduced in 1994, found its first application in NLP in 2016.
| Model | Tokenization Approach | Embeddings |
|---|---|---|
| BERT | WordPiece | Contextual with positional encodings, leveraging bidirectional context |
| T5 | SentencePiece | Contextual embeddings with positional encodings, in a text-to-text framework |
| LLaMA | Byte-Pair Encoding + SentencePiece | Contextual Rotary Position Embedding (RoPE), using deep Transformer architecture |
| GPT-4 | Byte-Pair Encoding (likely) | Contextual embeddings with positional encodings, using deep Transformer architecture (likely) |
Retrieval-augmented generation
Retrieval-augmented generation (RAG) gained significant attention lately as a highly relevant use case for embeddings. It is a way to enhance LLM prompts with supplementary information.
Key advantages provided by RAG include:
External knowledge database
While language models’ parameters can contain a wealth of information about the world, they have limitations in both capacity and the types of knowledge they were trained with. By fetching and providing the most relevant, private or highly specialized data, RAG can help overcome these limitations.
Context window expansion
Even the most advanced LLMs currently operate within a limited context window (typically between 4K and 32K tokens). Large volumes of text cannot be processed by them directly. This would require a combined retriever-generator model with the ability to store and fetch relevant information in an external memory, such as a vector database.
Since RAG engines interact with LLMs through text, it’s often more efficient to utilize entirely different embeddings than those employed within the LLM. The primary criteria for selecting these embeddings include the specifics of the added information, such as length, language, and domain.
Discriminative ML applications
While Generative AI has been attracting a lot of the attention recently, in practical terms, most of the current ML applications heavily rely on discriminative techniques. The real world solutions for tasks like classification, spam detection, speech recognition, and recommendations. While LLM possess the flexibility to address many of these challenges, specialized discriminative Deep Learning and classical ML approaches still yield superior results. In such scenarios, embeddings derived from large pre-trained Decoder-based models like BERT, RoBERTa, and T5 frequently serve as a valuable starting point.
Resource-constrained environments
LLMs offer remarkable capabilities but they come with significant resource requirements, making their application challenging in certain scenarios:
- High latency: LLMs are often limited in token output per second, resulting in high latency for tasks that require real-time responses.
- Low memory: On-device inference demands efficient memory utilization, and LLMs may struggle in resource-constrained environments.
- Large data volume: Processing each data record with LLMs can incur a substantial per-item cost, rendering them impractical for scenarios with massive data volumes.
Semantic search
Semantic search serves as a core component for solutions in information retrieval, question answering and content recommendation fields. Retrieval of similar items is a ’natural’ application for embeddings. The recent increase in the number of Vector DBs simplified the implementation of approximate nearest neighbour search components.
The Massive Text Embedding Benchmark (MTEB) provides a range of metrics related to semantic search, including Retrieval, Reranking, and Semantic Textual Similarity. These metrics aid in selecting the most effective embeddings technique.
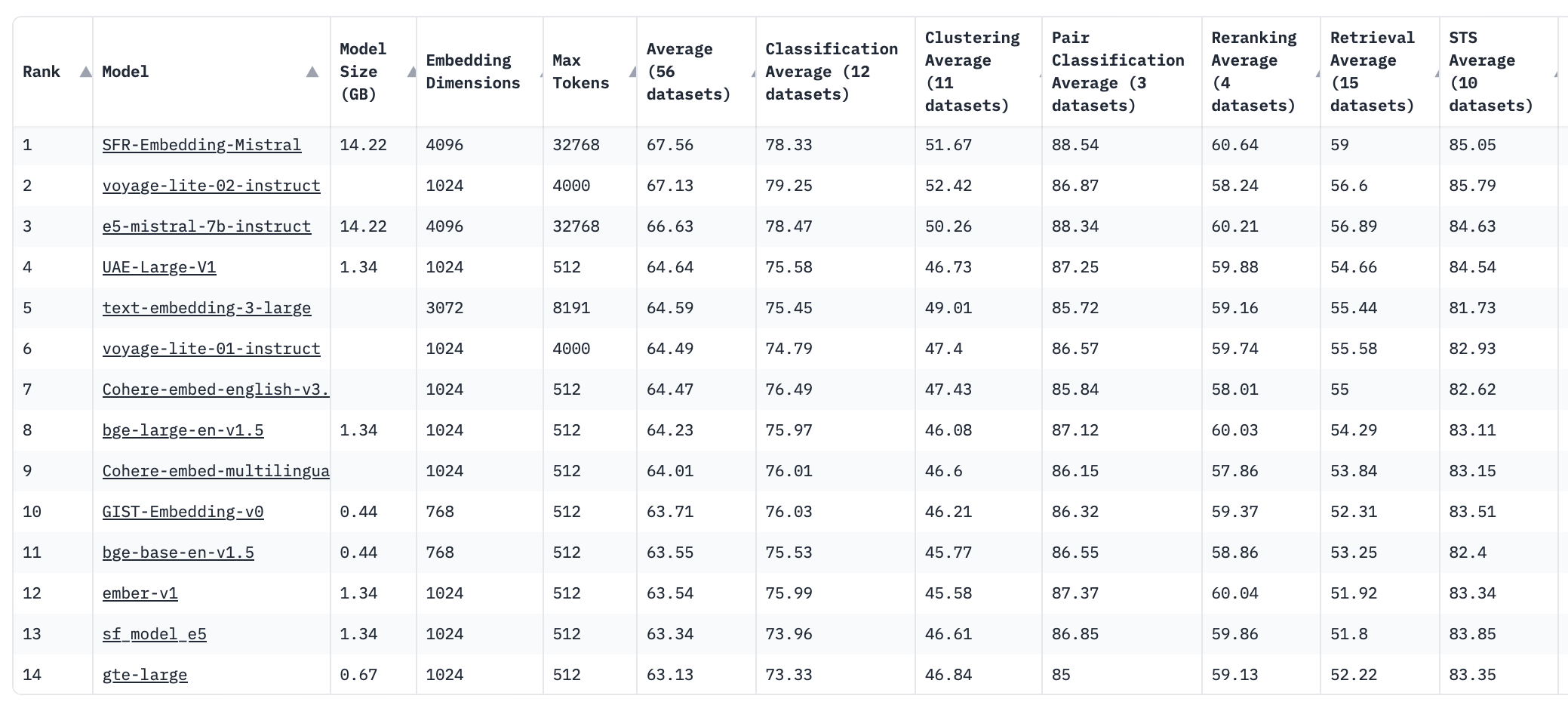
MTEB ranking of embeddings (Jan 2024)
Data exploration
The GIGO (garbage in, garbage out) principle in computer science never loses its relevance. Hence, data analysis and exploration remain pivotal in any practical project. In this domain, not only state-of-the-art but also ‘older’ non-contextual and sub-word tokenization embeddings techniques such as Word2Vec, GloVe, and Doc2Vec can serve as excellent starting points. Their simplicity and ease of interpretability become advantages during the data analysis stage.

Source: https://xkcd.com/1838/
Multiple techniques can be employed to analyze embedded text, including dimensionality reduction methods like PCA and t-SNE, further visualization, clustering, topic modeling, anomaly detection, and more.
In summary
The rise of LLMs has underscored and transformed the significance of text embeddings. These embeddings act as a fundamental element that enhances the generative capabilities of language models. Over the years, numerous specialized embedding techniques have been developed, establishing a foundational base for a wide range of NLP applications.